Hi Guys,
Today, let’s take a look at a NoSQL database-Apache Cassandra, which is an open source distributed database management system, initially developed by Facebook.
I. Apache Cassandra Introduction
A very good study material from DataStax
1) Some basic concept we should pay attention to
commit log-Please look at the session “writing and reading data”
memtable-Please look at the session “writing and reading data”
SSTable-Please look at the session “writing and reading data”
Bloom filter–checks the probability of an SSTable having the needed data
sharding–Relational databases and some NoSQL systems require manual, developer-driven methods for distributing data across the multiple machines of a database cluster.
partitioner–which determines how data is distributed across the nodes that make up a database cluster. In short, a partitioner is a hashing mechanism that takes a table row’s primary key, computes a numerical token for it, and then assigns it to one of the nodes in a cluster in a way that is predictable and consistent.
keyspaces–analogous to Microsoft SQL Server and MySQL databases or Oracleschemas.
replication—is configured at the keyspace level, allowing different keyspaces to have different replication models.
replication factor—The total number of data copies that are replicated is referred to as the A replication factor of 1 means that there is only one copy of each row in a cluster, whereas a replication factor of 3 means three copies of the data are stored across the cluster.
1) Architecture
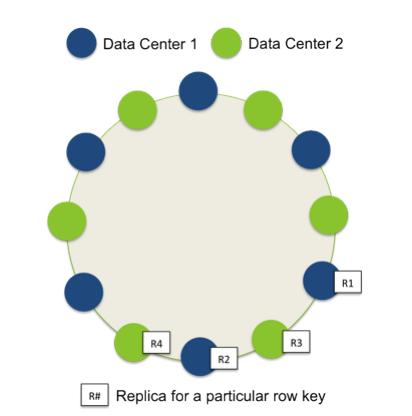
In Cassandra, all nodes play an identical role; there is no concept of a master node, with all nodes communicating with each other via a distributed, scalable protocol called “gossip.”
Cassandra’s built-for-scale architecture means that it is capable of handling large amounts of data and thousands of concurrent users or operations per second—even across multiple data centers—as easily as it can manage much smaller amounts of data and user traffic.
Cassandra’s architecture also means that, unlike other master-slave or sharded systems, it has no single point of failure and therefore is capable of offering true continuous availability and uptime.
Here’s an example image (refer to DataStax pdf),

2) Writing and Reading
Data written to a Cassandra node is first recorded in an on-disk commit log and then written to a memory-based structure called a memtable.
When a memtable’s size exceeds a configurable threshold, the data is written to an immutable file on disk called an SSTable.
Buffering writes in memory in this way allows writes always to be a fully sequential operation, with many megabytes of disk I/O happening at the same time, rather than one at a time over a long period. T
For a read request, Cassandra consults an in-memory data structure called a Bloom filter that checks the probability of an SSTable having the needed data.
If answer is a tenative yes, Cassandra consults another layer of in-memory caches, then fetches the compressed data on disk. If the answer is no, Cassandra doesn’t trouble with reading that SSTable at all, and moves on to the next.
3) About CQL (Cassandra Query Language)
Cassandra Query Language (CQL) is primary API used for interacting with a Cassandra cluster. CQL resembles the standard SQL used by all relational databases. So CQL is similar to other SQL languages.
4) Here are some well-knowned NoSQL database comparisons
1. Eleven kinds of NoSql database comparisons.
2. Cassandra vs MongoDB vs Neo4j
Note Cassandra supports MapReduce which makes it perfectly suitable to Hadoop and Spark and it is using token-ring architecture which is more reliable compared to HBase, which is the basic column-family database.
II. Let’s start our installation
ENV version
OS- Ubuntu-15.04
Apache Cassandra-2.1.7
1. Download and unzip Apache Cassandra
wget http://www.apache.org/dyn/closer.cgi?path=/cassandra/2.1.7/apache-cassandra-2.1.7-bin.tar.gz
tar -xvzf apache-cassandra-2.1.7-bin.tar.gz
mv apache-cassandra-2.1.7 /usr/local/cassandra
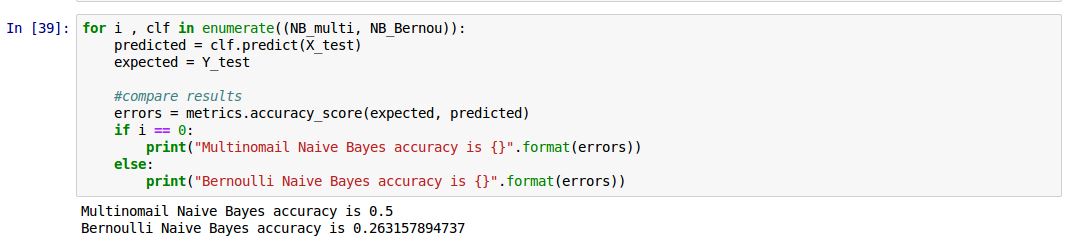
2. Two options to grant access to log folder.
Both of these methods are based on study of /conf/cassandra.yaml, which is the storage config file.
2.1 Create three log folders under. (refer to here, and these are related to the architecture we discussed above)
sudo mkdir /usr/local/cassandra/commitlog
sudo mkdir /usr/local/cassandra/data
sudo mkdir /usr/local/cassandra/saved_caches
2.2 make directories and grant access (refer to this)
sudo mkdir /var/lib/cassandra
sudo mkdir /var/log/cassandra
sudo chown -R $USER:$GROUP /var/lib/cassandra
sudo chown -R $USER:$GROUP /var/log/cassandra
3. Add environment variables to ~/.bashrc
export CASSANDRA_HOME=~/cassandra
export PATH=$PATH:$CASSANDRA_HOME/bin
4. Per-thread stack size issue
For Cassandra-2.1.7, the per-thread stack size in ../conf/cassandra-env.sh, is already increased to 256K, which iis good enough for us.
5. Start Cassandra
cd /usr/local/cassandra
bin/cassandra -f //-f means start in foreground

If the terminal hanging at here, it is successfully started.
6. Let’s open another terminal and try some CQL statement
cd /usr/local/cassandra
bin/cqlsh

Notice this shell is running on the 127.0.0.1:9042 which is exactly the CQL client ip address showed up in the previous step.
7. Basic CQL
Note: remember to use keyspace first to create tables.
Code is refer to here,
CREATE KEYSPACE Demo WITH REPLICATION = {‘class’: ‘SimpleStrategy’, ‘replication_factor’:3};
use Demo;
CREATE TABLE users (user_name varchar PRIMARY KEY, password varchar, gender varchar, session_token varchar, state varchar, birth_year bigint);
select * from system.schema_keyspaces;
describe tables;
describe keyspaces;
describe table users;


Congratulations~, we have studied the basic architecture and installation of Apache Cassandra!
Reference
1. https://www.youtube.com/watch?v=ZK0hQl9VPBY
2. https://www.digitalocean.com/community/tutorials/how-to-install-cassandra-and-run-a-single-node-cluster-on-a-ubuntu-vps
3. http://www.datastax.com/doc-source/pdf/cassandra11.pdf


 “)
“)












 , where
, where 



















 .
.